 Problem S. 68. (January 2012)
Problem S. 68. (January 2012)
S. 68. One method to compress data is Huffman coding. In problem I. 276, you had to make a presentation about the coding process. Now you have to create a program to do the Huffman coding.
The Huffman coding replaces each byte of the original file with a sequence of bits of variable length: less frequent bytes will be replaced by longer, whereas more frequent bytes by shorter bit sequences. To create the Huffman code, a binary tree should be created first according to the frequencies of the original bytes, then this tree should be traversed appropriately. The tree is built up as follows.
1. First, each byte is considered as an isolated node of the graph. The node has no branches. The value of the node is the frequency of the actual character.2. Then the two nodes with the least frequencies are merged: they will be the left and right branches of a new node whose value is the sum of the frequencies of the original two nodes. Then the original two nodes are deleted.
3. The previous step is repeated until only one node remains.
Now the Huffman code of a character is obtained by walking from the root to the actual character: each left step is a 0, while a right step is a 1 bit.
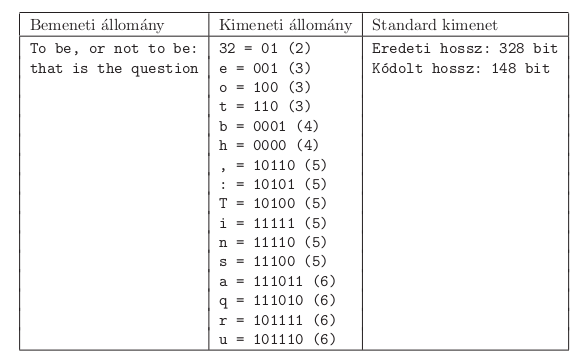
Your program s68 should create a possible Huffman code. The first command line argument is the name of the input file to be encoded. The second command line argument is the name of the output text file: each line should contain the sequence of bits (and their length) corresponding to each original byte. Lines of the output should be sorted according to the length of the bit sequences, then according to alphabetical order of the original bytes, as in the example. Non-printable ASCII characters and the space character should be displayed as their corresponding ASCII codes. Your program should also display the length in bits of the original file and the encoded file on the standard output.
In the table, ``Bemeneti állomány'' is the input file, ``Kimeneti állomány'' is the output file, ``Standard kimenet'' is the standard output, ``Eredeti hossz'' is the original length, while ``Kódolt hossz'' is the length of the encoded text.
The source code (s68.pas, s68.cpp, ...) without the .exe or any other auxiliary files generated by the compiler but with a short documentation (s68.txt, s68.pdf, ...) -- also describing which developer environment to use for compiling, further a brief description of your solution -- should be submitted in a compressed file s68.zip.
(10 pont)
Deadline expired on February 10, 2012.
Sorry, the solution is available only in Hungarian. Google translation
Mintamegoldásként Adrián Patrik debreceni 12. osztályos tanuló kritika és dokumentációját (s68ap-kritika-dokumentacio.pdf) valamint programját (s68ap.c), és Szabó Attila pécsi 11. osztály diák dokumentációját (s68sza.pdf) valamint programját(s68sza.c) adjuk közre.
Statistics:
15 students sent a solution. 10 points: Adrián Patrik, Hoffmann Áron, Jákli Aida Karolina, Kucsma Levente István, Szabó 928 Attila. 9 points: Havasi 0 Márton, Marussy Kristóf, Strenner Péter. 8 points: 1 student. 7 points: 4 students. 6 points: 2 students.
Problems in Information Technology of KöMaL, January 2012