KöMaL Problems in Informatics, October 2011
Please read the rules of the competition.
Show/hide problems of signs:
 |
Problems with sign 'I'Deadline expired on November 10, 2011. |
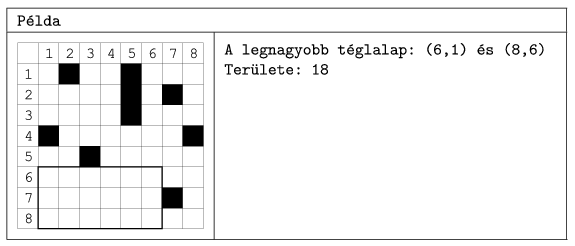
I. 274. We are given an n×m rectangular grid (1 n,m500) consisting of black and white squares. Your task is to locate the rectangle with maximal area containing only white cells. Coordinates of the upper left and lower right corners together with the area of the rectangle should be given as an output.
n,m500) consisting of black and white squares. Your task is to locate the rectangle with maximal area containing only white cells. Coordinates of the upper left and lower right corners together with the area of the rectangle should be given as an output.
In the ``Példa'' example, ``A legnagyobb téglalap'' is ``the largest rectangle'', and ``Területe'' is ``with area''.
For the solution, you may consider the following method for relatively small values of n and m: by using nested loops, test all possible rectangles given by coordinate pairs whether they contain any black cells, then select the rectangle with maximal area. However, the running time of this algorithm is high when the number of elements is increased, because the number of comparisons is proportional to the 4th power of the number of elements.
So the following hint may be useful: compute and store for each cell the number of black cells in the rectangle with lower right corner being the actual cell.
The table ``A fenti példához számolt értékek'' shows these numbers corresponding to the above example.
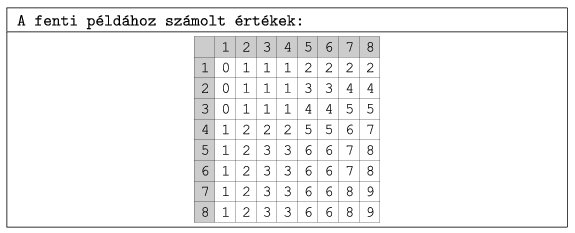
By using these values, the number of black cells in a rectangle given by two coordinate pairs can be determined without loops.
Your program i274 should find the largest rectangle containing only white cells.
The size of the grid and the colors of the cells (0: white, 1: black) are contained in the input file. The first line of this file gives the number of rows (n) and the number of columns (m). Then each of the following n lines contains m values (without spaces) and describes the state of each cell (0 or 1).
The result, that is the upper left and lower right coordinates of the maximal rectangle together with its area, should be displayed on the screen. The only command line argument to your program is the name of the input file. The total running time of your program should be less than 60 seconds on a 2.40 GHz, Core2Duo computer.
In the last table, ``Példa a bemenetre'' is a sample input, while ``Kimenet'' is the corresponding output.

The source code (i274.pas, i274.cpp, ...) together with a short documentation of your program and solution (i274.txt, i274.pdf, ...) -- also specifying the name of the developer environment to use for compiling the source file -- should be submitted in a compressed file i274.zip.
(10 pont)
solution (in Hungarian), statistics
I. 275. The file hatar.txt contains some data on the border stations of Hungary and its neighboring countries.
1. Create a new database with name allomasok (stations). Import the data table into the database with name hatar (border). Field names are contained in the first line of the tabulator separated txt data file in UTF-8 encoding.
2. After importing, set the appropriate data formats and the key. Add a unique identifier with name az to the table.
Table:

Now solve the following task. When a query is answered, no other data, only the requested results should appear. Queries should be named as indicated in the parentheses.
3. By using a query, list in alphabetical order the name of the Hungarian settlements of the border railway stations to Slovakia. (3szlovak)
4. List the name of those neighboring countries toward which there are less than 3 border railway stations. (4keves)
5. Make a query that gives the number of railway, highway and planned border stations. Based on this query, create a report to group these results according to countries. Adjust the column width properly in the report such that all data should be visible but columns should not be too wide. The title of the query should be ``Átkel őhelyek száma'' (number of border stations). (5osszesites)
6. Make a query to list all data of those border stations where the name of one of the two settlements contains the name of the other. (6hasonlok)

7. List by a query the name of those Hungarian settlements where there are both railway and highway border stations. The list should contain each settlement's name only once and in alphabetical order. (7kozutesvasut)
8. List by a query the name of those Hungarian settlements having joint border stations with more neighboring settlements. Each name should appear once in this list. (8tobb)
9. Make a form according to table hatar as in the example. Create two control buttons to scroll the records. (9urlap)
10. By using a query, and as in the example, list by countries the number of railway and highway border stations. (10tabla)  In the example, ``orszag'' is country, ``vasúti határátkelők'' is ``border railway stations'', while ``közúti átkelők`` is ``highway stations''.
In the example, ``orszag'' is country, ``vasúti határátkelők'' is ``border railway stations'', while ``közúti átkelők`` is ``highway stations''.
The database (i275.accdb, i275.odb, ...) together with a short documentation (i275.txt, i275.pdf) - also containing the name and version number of the database application - should be submitted in a compressed file (i275.zip).
(10 pont)
solution (in Hungarian), statistics
I. 276. Huffman coding is an algorithm to compress data. You should get familiar with the algorithm to some extent and make a presentation about it. By using the string ``INFORMATIKA + MATEMATIKA'', demonstrate the steps of creating the code. Your presentation should be as clear as possible, show each step of the encoding process, and should contain an animation in the case, e.g., of creating and visiting the tree. Create action buttons to switch between slides and start the animation.
The file containing your presentation (i276.pptx, i276.odp,. . . ) should be submitted in a compressed file i276.zip.
(10 pont)
 |
Problems with sign 'S'Deadline expired on November 10, 2011. |
S. 65. Even in the ancient Aztec empire they found it necessary to encrypt messages issued by the rulers. According to the famous archeologist, Prof. Stoory, codes were based on the two symbols of Ometeotl, the lord of the duality: the < symbol representing masculine force, and the symbol > representing feminine affection. It was only allowed to create strings that obeyed the following two rules:
-- according to the principle of balance, each string should contain the same number of < and > symbols,
-- reading from left to right, up to any symbol, the number of masculine symbols should be greater than or equal to that of the feminine symbols. In other words, symbols representing force and activity precede symbols representing affection and passivity.
Strings of the above type can be sorted according to their length and the position of the < symbols:
(1) shorter strings are listed first, and
(2) if two strings have the same length, lexicographic ordering is used: the order is determined by the first character, but if they are the same, then by the second character, and so on.
For example, the order of the strings of length at most 6 is the following:
<>
<<>>
<><>
<<<>>>
<<><>>
<<>><>
<><<>>
<><><>
Therefore we have an (infinite) ordered list R of symbols < and >. Then the steps for creating the code by the Aztecs were the following:
(1) The letters of the language (for the sake of simplicity, we now use the lowercase English alphabet) together with the space character are represented by the digits of the number system in base 27 (,
,
, . . . ,
).
(2) The message is split into blocks of length b (if the length of the message is not a multiple of b, the minimal number of spaces is added to the right to make it divisible).
(3) Then blocks are interpreted as integers in base 27.
(4) Finally they select the corresponding <, > symbol strings from the above list R (the number of the string in R is the same as the number they got in Step 3), space separators are inserted between each block, and these strings are concatenated.
Your program should be able to encode and decode messages from the ruler.
The first line of the input file contains the block length b (1b12). The second line contains a character string to be encoded or decoded. Except for the spaces, a string to be encoded contains only lowercase letters of the English alphabet, while strings to be decoded only the < and > characters. We may assume that the input does not begin with a space.
The only line of the output file should contain the result of the encoding or decoding.
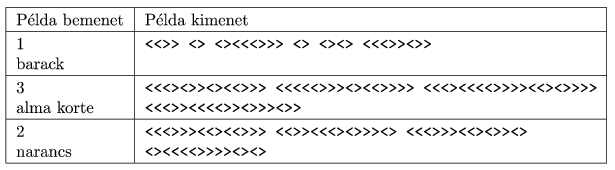
In the example, ``Példa bemenet'' is the sample input, while ``Példa kimenet'' is the sample output. We remark that in the example there may be line breaks instead of certain space characters.
(10 pont)
$Var(Body)
Upload your solutions above