
A KöMaL 2011. októberi informatika feladatai
Kérjük, ha még nem tetted meg, olvasd el a versenykiírást.
Feladat típusok elrejtése/megmutatása:
 |
I-jelű feladatokA beküldési határidő 2011. november 10-én LEJÁRT. |
I. 274. Adott egy n×m-es (1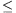 n,m500) téglalap alakú terület, amely fekete és fehér négyzetekből áll. Keressük meg ebben azt a legnagyobb téglalapot, amely csak fehér cellákat tartalmaz. Az eredményt a téglalap bal felső és jobb alsó sarkának a koordinátáival és a területével adjuk meg.
n,m500) téglalap alakú terület, amely fekete és fehér négyzetekből áll. Keressük meg ebben azt a legnagyobb téglalapot, amely csak fehér cellákat tartalmaz. Az eredményt a téglalap bal felső és jobb alsó sarkának a koordinátáival és a területével adjuk meg.
Érdemes meggondolni, hogy n és m viszonylag kis értéke mellett használható módszer, hogy az összes koordináta-párral meghatározott valamennyi téglalap fekete cella-mentességét egymásba ágyazott ciklusokkal ellenőrizzük, majd ezekből a maximális területűt kiválasztjuk. Az összehasonlítások száma az elemek számának negyedik hatványával lesz arányos és ez a futási időt az elemszám növelésével rendkívül megnöveli.
Megoldási ötlet: Számítsuk ki előre és tároljuk el minden cellához, hogy a terület bal felső sarkával együtt téglalapot alkotva hány fekete cellát tartalmaz.
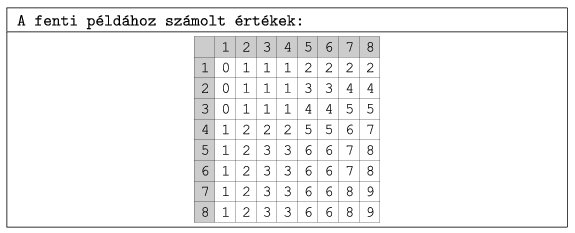
Az így előkészített értékekkel két koordináta-párral megadott téglalap fekete cella-tartalma ciklusok nélkül kiszámítható.
Készítsünk programot i274 néven, amely meghatározza a legnagyobb téglalapot, amely csak fehér cellákat tartalmaz.
A program a terület nagyságát és a cellák színét (0: fehér és 1: fekete) fájlból olvassa be. A fájl első sora a sorok számát (n) és az oszlopok számát (m) adja meg. Az ezt követő n darab sorban szereplő m darab érték, a példa szerint szóköz elválasztása nélkül, pedig a megfelelő cellák állapotát (0 vagy 1) írja le.
Az eredményt, azaz a téglalap bal felső és jobb alsó sarkainak koordinátáit és a téglalap területét a képernyőn jelenítjük meg. A program egyetlen parancssori argumentuma a bemeneti fájl legyen. A program futtatási ideje maximum 60 másodperc a tesztelésre használt 2.40 GHz, Core2Duo processzorú számítógépen.

Beküldendő egy tömörített i274.zip állományban a program forráskódja (i274.pas, i274.cpp, ...) és a program rövid dokumentációja (i274.txt, i274.pdf, ...), amely tartalmazza a megoldás rövid leírását, és megadja, hogy a forrásállomány melyik fejlesztő környezetben fordítható.
(10 pont)
I. 275. Magyarország és szomszédos országai határátkelő állomásainak néhány legfontosabb adatát tartalmazza a hatar.txt állomány.
1. Készítsünk új adatbázist allomasok néven. Importáljuk az adattáblát az adatbázisba hatar néven. A txt típusú adatállomány tabulátorokkal tagolt UTF-8 kódolású, és az első sora tartalmazza a mezőneveket.
2. Beolvasás után állítsuk be a megfelelő adatformátumokat és a kulcsot. A táblához adjunk hozzá az néven egyedi azonosítót.
Tábla:

Készítsük el a következő feladatok megoldását. Az egyes lekérdezéseknél ügyeljünk arra, hogy mindig csak a kért értékek jelenjenek meg és más adatok ne. A megoldásainkat a zárójelben lévő néven mentsük el.
3. Írassuk ki lekérdezés segítségével Szlovákia felé a vasúti határátkelők magyarországi településinek nevét ábécérendben. (3szlovak)
4. Adjuk meg azoknak a szomszéd országoknak a nevét, a melyek felé háromnál kevesebb vasúti határátkelőhely van. (4keves)
5. Készítsünk lekérdezést, amely országonként a vasúti, a közúti és a tervezett határátkelők számát adja meg. A létrehozott lekérdezés alapján készítsünk jelentést, amely az ország neve szerint csoportosítva jeleníti meg az eredményeket. Az elkészített jelentésben az oszlopok szélességét állítsuk be úgy, hogy minden adat látszódjon, de feleslegesen széles ne legyen. A lekérdezés címének írjuk be, hogy ,,Átkelőhelyek száma''. (5osszesites)
6. Készítsünk lekérdezést, amely felsorolja azoknak a határátkelőknek minden adatát, ahol a két település egyikének neve a másikat tartalmazza. (6hasonlok)

7. Soroljuk fel lekérdezés segítségével azoknak a magyar településeknek a nevét, ahol közúti és vasúti határátkelőhely is van. A listában a települések neve egyszer, ábécérendben jelenjen meg. (7kozutesvasut)
8. Lekérdezéssel listázzuk ki azoknak a magyar településeknek a nevét, amelyeknek több szomszédos településsel van határátkelője. A listában minden név egyszer szerepeljen. (8tobb)
9. Készítsünk űrlapot a hatar tábla alapján a mintának megfelelően. A rekordléptetéshez tegyünk fel két vezérlőgombot. (9urlap)
10. Lekérdezéssel készítsük el országonként a vasúti és közúti határátkelők számát a minta szerint. (10tabla)

Beküldendő egy tömörített i275.zip állományban az adatbázis (i275.accdb, i275.odb, ...) valamint egy rövid dokumentáció (i275.txt, i275.pdf), amelyből kiderül az alkalmazott adatbázis-kezelő neve, verziószáma.
(10 pont)
I. 276. Adatok tömörítésének egyik lehetséges módja a Huffman-kódolás. Nézzünk utána az eljárásnak, és készítsünk prezentációt a bemutatására. A kód létrehozásának lépéseit az ``INFORMATIKA + MATEMATIKA'' karaktersorozat segítségével szemléltessük. A bemutató tegye minél érthetőbbé a tömörítés egyes lépéseit, tartalmazzon animációt, például a fa felépítése és bejárása esetén. Az egyes diák közötti váltást és az animációk indulását akciógombok segítségével oldjuk meg.
Beküldendő egy tömörített i276.zip állományban a prezentációt tartalmazó állomány (i276.pptx, i276.odp, ...).
(10 pont)
 |
S-jelű feladatokA beküldési határidő 2011. november 10-én LEJÁRT. |
S. 65. Már a korabeli azték birodalom fénykorában is szükségesnek látták az uralkodói üzenetek titkosítását. A neves régész, Kamoo professzor szerint a kódolás alapja Ometeotl, a kettőség istenének két jele: a férfias erőt (<) és a női gyengédséget (>) jelképező két szimbólum volt. Ezekből az istenség parancsára csak az alábbi két szabály betartásával volt szabad jelsorozatokat létrehozni:
-- érvényesülnie kellett az egyensúlynak, tehát azonos számú < és > jel szerepelt minden sorozatban;
-- balról-jobbra olvasva a sorozatot annak tetszőleges jeléig mindig több, vagy azonos számú férfi szimbólum szerepelt, mint női szimbólum, tehát az erőt és aktivitást jelképező szimbólumok mindig megelőzték a gyengédséget és passzivitást jelölő szimbólumokat.
A vázolt módon létrehozhatóak különböző hosszúságú jelsorozatok, melyek sorba rendezhetők a hosszúságuk, illetve a < jelek elhelyezkedése alapján:
(1) A rövidebb jelsorozatok előbb vannak, mint a hosszabbak;
(2) az azonos hosszúságúakon lexikografikus rendezést alkalmazunk (ha tudunk, akkor az első betű alapján döntünk; ha ezek megegyeznek, akkor a második alapján stb.).
Például a legföljebb hat hosszúságú jelsorozatok sorrendje:
<>
<<>>
<><>
<<<>>>
<<><>>
<<>><>
<><<>>
<><><>
Ennek alapján tehát van egy (végtelen hosszú) rendezett R listája a < és > szimbólumokból álló jelsorozatoknak. Ezután a kódolás egyes lépései a következők voltak:
(1) A nyelv betűi (az egyszerűség kedvéért az angol ábécét használjuk) és a szóköz megfelelnek a 27-es számrendszer számjegyeinek (,
,
, ...,
);
(2) az üzenetet b hosszúságú blokkokra bontjuk (ha a szöveg hossza nem osztható b-vel, akkor szóközökkel kipótolják a végét);
(3) az egyes blokkokat kiolvassuk 27-es számrendszerbeli számokként;
(4) az így kapott számoknak megfelelő sorszámú jelsorozatokat kiválasztjuk a fenti R listából és ezeket szóközökkel elválasztva egymás után írjuk.
Készítsünk programot ami képes kódolni, illetve dekódolni az uralkodó üzeneteit.
A bemeneti állomány első sorában a blokkok b hossza szerepel (1b12). A második sorban egy kódolandó vagy dekódolandó karaktersorozat szerepel. A szóközökön kívül, az előbbiekben csak az angol ábécé kisbetűi, az utóbbiakban pedig csak a < és > karakterek szerepelnek. Feltehetjük, hogy a bemenet nem kezdődik szóközzel.
A kimeneti állomány egyetlen sorába a kódolás vagy dekódolás eredményét írjuk.
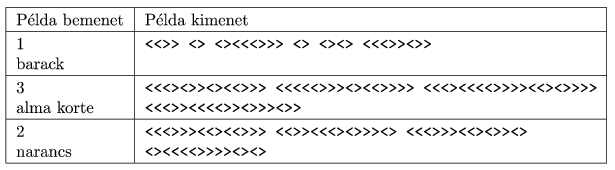
Megjegyzés: A példákban a kódolt üzenetekben a szóközök helyett néhol sortörések látszanak.
(10 pont)
Figyelem!
Az informatika feladatok megoldásait ne e-mailben küldd be! A megoldásokat az Elektronikus munkafüzetben töltheted fel.
|
|